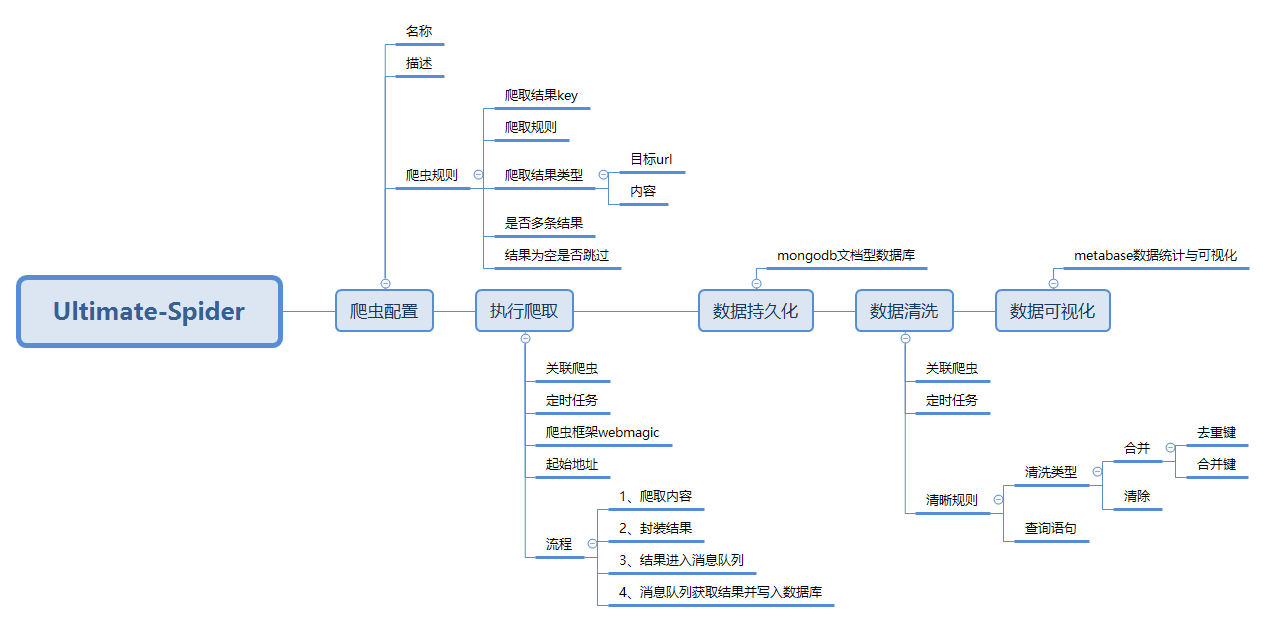
Ultimate Spider【终极蜘蛛王】,一款用于网络数据采集的工具。本文对Ultimate Spider的整体架构和一些技术亮点作说明。
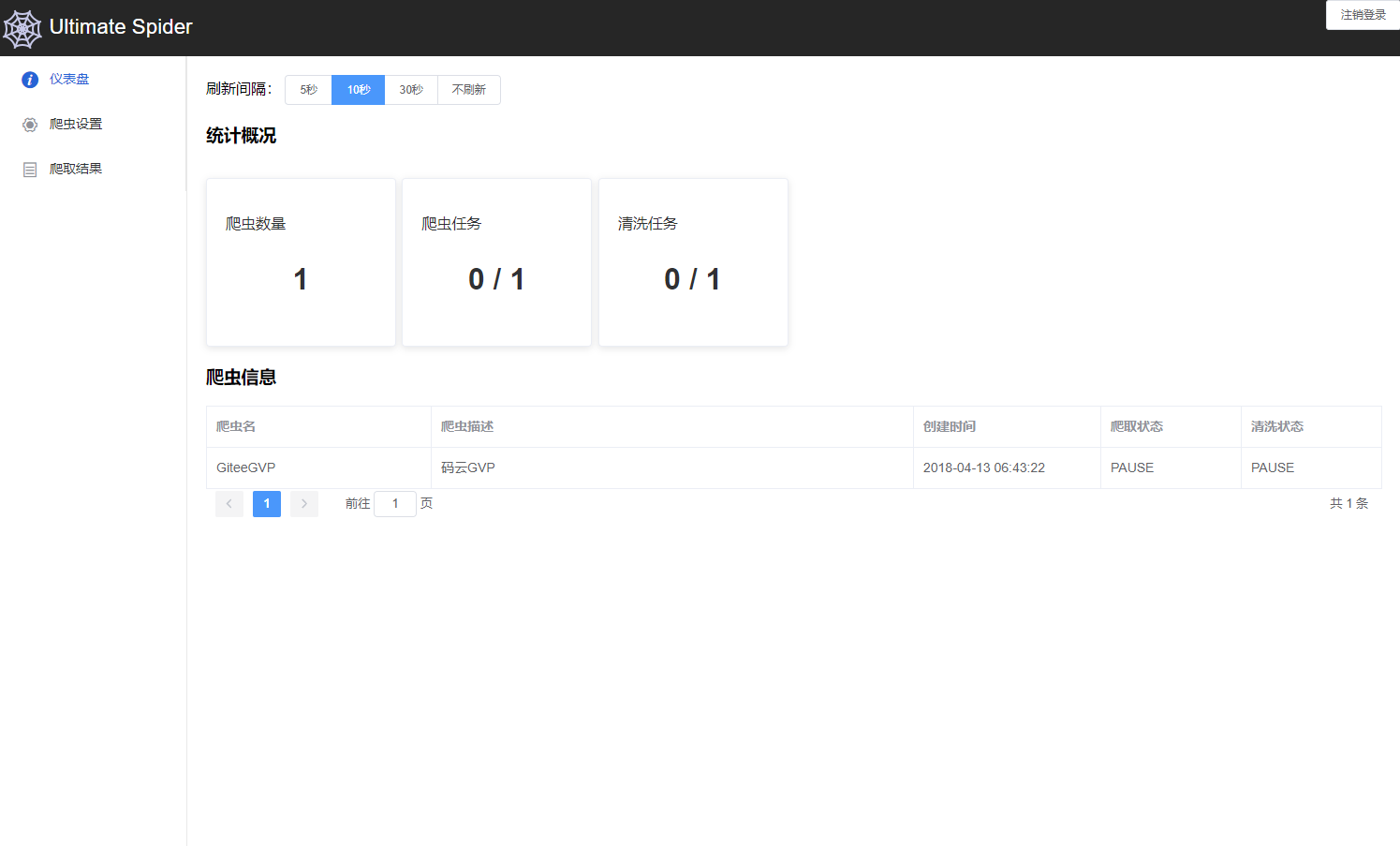
Ultimate Spider主要页面有:1、用来展示概览信息的仪表盘页;2、爬虫配置页。
整体架构如下图所示:
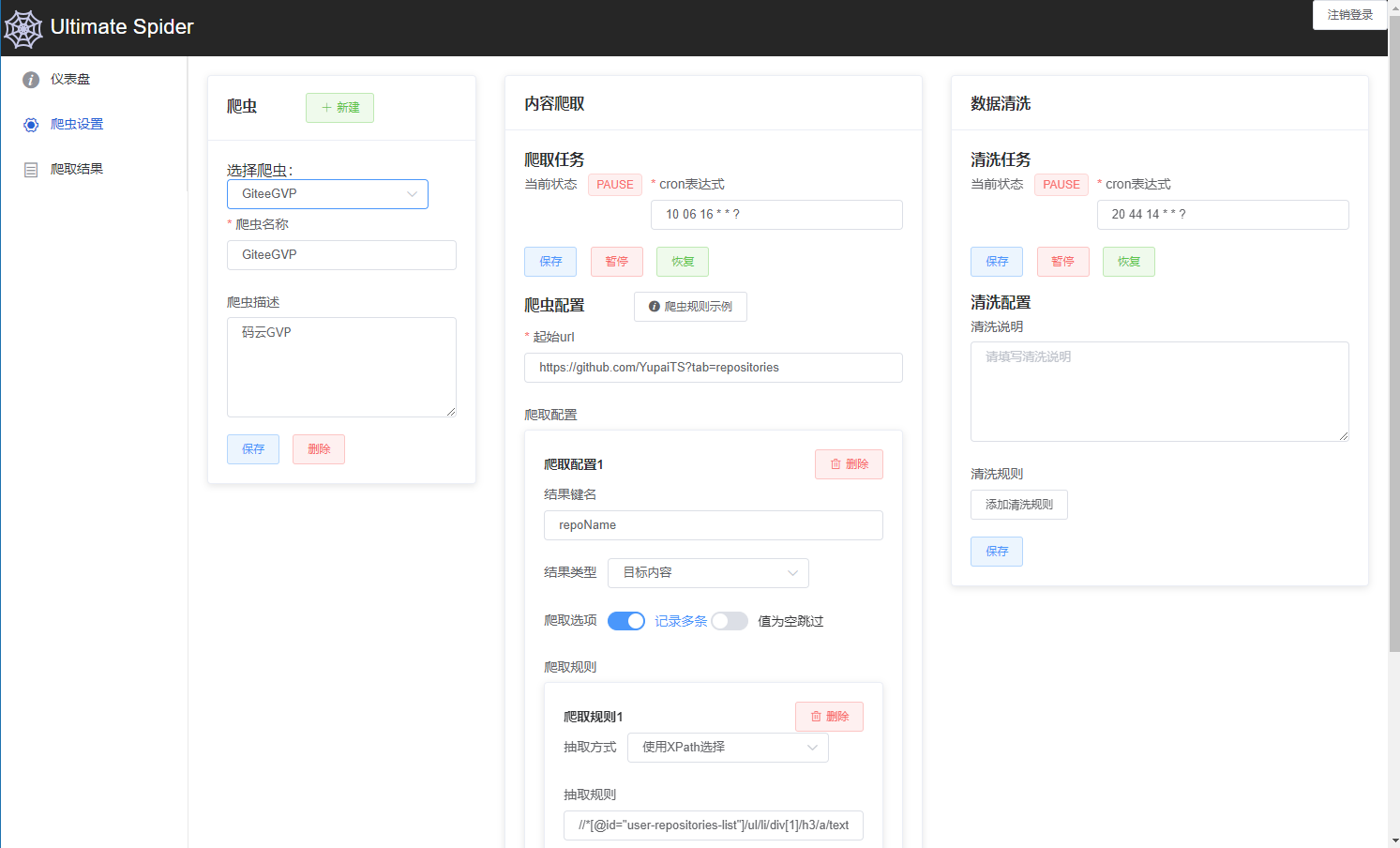
爬虫配置
在WebMagic爬虫框架的基础上对初始Url和爬取内容进行可视化配置,爬取规则的制定更加灵活多变,适应范围更广。
- SpiderProcessor.java 根据爬取规则进行爬取
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
| @Slf4j
@EnableConfigurationProperties({SpiderProperties.class})
public class SpiderProcessor implements PageProcessor {
private SpiderProperties spiderProperties;
private String spiderName;
private Crawler crawler;
public SpiderProcessor(SpiderProperties spiderProperties, String spiderName, Crawler crawler) {
this.spiderProperties = spiderProperties;
this.spiderName = spiderName;
this.crawler = crawler;
}
@Override
public void process(Page page) {
if (CollectionUtils.isNotEmpty(crawler.getCrawlConfigs())) {
page.putField(Constants.SPIDER_NAME, spiderName);
JSONObject content = new JSONObject();
for (Crawler.CrawlConfig crawlConfig : crawler.getCrawlConfigs()) {
if (CollectionUtils.isNotEmpty(crawlConfig.getCrawlRules())) {
Selectable selector = page.getHtml();
for (Crawler.CrawlRule crawlRule : crawlConfig.getCrawlRules()) {
switch (crawlRule.getCrawlType()) {
case XPATH:
selector = selector.xpath(crawlRule.getRule());
break;
case CSS:
if (StringUtils.isBlank(crawlRule.getAttr())) {
selector = selector.css(crawlRule.getRule());
} else {
selector = selector.css(crawlRule.getRule(), crawlRule.getAttr());
}
break;
case LINKS:
selector = selector.links();
break;
case REGEX:
selector = selector.regex(crawlRule.getRule());
break;
case REGEX_WITH_GROUP:
selector = selector.regex(crawlRule.getRule(), crawlRule.getGroup());
break;
case REPLACE:
selector = selector.replace(crawlRule.getRule(), crawlRule.getReplacement());
break;
default:
log.warn("not support crawl rule type: {}", crawlRule.getCrawlType());
}
}
if (crawlConfig.isMultiResult()) {
List<String> value = selector.all();
if (crawlConfig.isNullSkip() && CollectionUtils.isEmpty(value)) {
page.setSkip(true);
break;
}
if (crawlConfig.getCrawlResultType() == Crawler.CrawlResultType.TARGET_URL) {
page.addTargetRequests(value);
} else if (crawlConfig.getCrawlResultType() == Crawler.CrawlResultType.TEXT) {
content.put(crawlConfig.getCrawlKey(), value);
} else {
log.warn("not support crawl result type: {}", crawlConfig.getCrawlResultType());
}
} else {
String value = selector.get();
if (crawlConfig.isNullSkip() && StringUtils.isBlank(value)) {
page.setSkip(true);
break;
}
if (crawlConfig.getCrawlResultType() == Crawler.CrawlResultType.TARGET_URL) {
page.addTargetRequest(value);
} else if (crawlConfig.getCrawlResultType() == Crawler.CrawlResultType.TEXT) {
content.put(crawlConfig.getCrawlKey(), value);
} else {
log.warn("not support crawl result type: {}", crawlConfig.getCrawlResultType());
}
}
}
}
content.put(Constants.CRAWL_AT, new Date());
page.putField(Constants.SPIDER_CONTENT, content);
}
}
@Override
public Site getSite() {
return Site.me()
.setRetryTimes(spiderProperties.getRetryTimes())
.setRetrySleepTime(spiderProperties.getRetrySleepTime())
.setSleepTime(spiderProperties.getSleepTime())
.setTimeOut(spiderProperties.getTimeout());
}
}
|
爬虫执行
使用Quartz定时任务框架完成爬虫任务的调度,可以随时暂停和恢复爬虫任务。
- TaskServiceImpl.java 爬虫任务服务实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
| @Slf4j
@Service
public class TaskServiceImpl implements TaskService {
@Autowired
private Scheduler scheduler;
@Autowired
private TaskRepository taskRepository;
@Autowired
private UltimateSpiderRepository ultimateSpiderRepository;
@Override
public Result getSpiderTask(Integer spiderId) {
if (!ValidateUtils.validId(spiderId)) {
return Result.fail(ResultCode.PARAMS_ERROR);
}
Task crawlTask = taskRepository.findOneBySpiderIdAndTaskType(spiderId, Task.TaskType.CRAWL);
Task cleanTask = taskRepository.findOneBySpiderIdAndTaskType(spiderId, Task.TaskType.CLEAN);
JSONObject spiderTask = new JSONObject();
spiderTask.fluentPut(Constants.CRAWL_TASK, crawlTask).fluentPut(Constants.CLEAN_TASK, cleanTask);
return Result.ok(spiderTask);
}
@Transactional(rollbackFor = Exception.class)
@Override
public Result saveTask(Task task) throws SchedulerException {
if (!task.isValid(false)) {
return Result.fail(ResultCode.PARAMS_ERROR);
}
if (task.getJobStatus() == null) {
task.setJobStatus(Task.JobStatus.RUNNING);
}
Task flushedTask = taskRepository.saveAndFlush(task);
UltimateSpider spider = ultimateSpiderRepository.findOne(task.getSpiderId());
JobKey jobKey = JobUtils.generateJobKey(spider, task.getTaskType());
if (task.getJobStatus() == Task.JobStatus.RUNNING) {
TriggerKey triggerKey = JobUtils.generateTriggerKey(spider, task.getTaskType());
Trigger trigger = TriggerBuilder.newTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule(task.getCronExpression()))
.withIdentity(triggerKey)
.build();
if (scheduler.checkExists(jobKey)) {
scheduler.rescheduleJob(triggerKey, trigger);
} else {
JobDetail jobDetail = JobBuilder.newJob(task.getTaskType().getJobClass())
.withIdentity(jobKey)
.usingJobData(Constants.JOB_TASK_ID, flushedTask.getId())
.storeDurably()
.build();
scheduler.scheduleJob(jobDetail, trigger);
}
} else if (task.getJobStatus() == Task.JobStatus.PAUSE) {
if (scheduler.checkExists(jobKey)) {
scheduler.pauseJob(jobKey);
}
}
return Result.ok(flushedTask);
}
@Transactional(rollbackFor = Exception.class)
@Override
public Result pauseTask(Integer id) throws SchedulerException {
if (!ValidateUtils.validId(id)) {
return Result.fail(ResultCode.PARAMS_ERROR);
}
Task task = taskRepository.findOne(id);
if (task == null || !task.isValid(false)) {
return Result.fail(ResultCode.DATA_VALID_ERROR);
}
UltimateSpider spider = ultimateSpiderRepository.findOne(task.getSpiderId());
JobKey jobKey = JobUtils.generateJobKey(spider, task.getTaskType());
if (scheduler.checkExists(jobKey)) {
scheduler.pauseJob(jobKey);
}
task.setJobStatus(Task.JobStatus.PAUSE);
taskRepository.save(task);
return Result.ok();
}
@Override
public Result resumeTask(Integer id) throws SchedulerException {
if (!ValidateUtils.validId(id)) {
return Result.fail(ResultCode.PARAMS_ERROR);
}
Task task = taskRepository.findOne(id);
if (task == null || !task.isValid(false)) {
return Result.fail(ResultCode.DATA_VALID_ERROR);
}
resumeTask(task);
task.setJobStatus(Task.JobStatus.RUNNING);
taskRepository.save(task);
return Result.ok();
}
@Override
public void resumeTask(Task task) throws SchedulerException {
UltimateSpider spider = ultimateSpiderRepository.findOne(task.getSpiderId());
JobKey jobKey = JobUtils.generateJobKey(spider, task.getTaskType());
if (scheduler.checkExists(jobKey)) {
scheduler.resumeJob(jobKey);
} else {
JobDetail jobDetail = JobBuilder.newJob(task.getTaskType().getJobClass())
.withIdentity(jobKey)
.usingJobData(Constants.JOB_TASK_ID, task.getId())
.storeDurably()
.build();
TriggerKey triggerKey = JobUtils.generateTriggerKey(spider, task.getTaskType());
Trigger trigger = TriggerBuilder.newTrigger()
.withSchedule(CronScheduleBuilder.cronSchedule(task.getCronExpression()))
.withIdentity(triggerKey)
.build();
scheduler.scheduleJob(jobDetail, trigger);
}
}
}
|
数据清洗
数据清洗任务同样使用Quartz进行调度,确保爬取数据的质量。清洗规则同样可在页面上进行配置。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| @Slf4j
public class CleanerJob implements Job {
@Autowired
private UltimateSpiderRepository ultimateSpiderRepository;
@Autowired
private TaskRepository taskRepository;
@Autowired
private CleanerRepository cleanerRepository;
@Autowired
private MongoTemplate mongoTemplate;
@Override
public void execute(JobExecutionContext jobExecutionContext) throws JobExecutionException {
Integer taskId = (Integer) jobExecutionContext.getJobDetail().getJobDataMap().get(Constants.JOB_TASK_ID);
Task task = taskRepository.findOne(taskId);
UltimateSpider ultimateSpider = ultimateSpiderRepository.findOne(task.getSpiderId());
Cleaner cleaner = cleanerRepository.findOneBySpiderId(task.getSpiderId());
if (cleaner == null || !cleaner.isValid(true)) {
log.warn("[{}] cleaner is invalid", ultimateSpider.getSpiderName());
return;
}
log.info("[{}] cleaner start", ultimateSpider.getSpiderName());
List<JSONObject> purgeList = Lists.newArrayList();
List<JSONObject> mergeList = Lists.newArrayList();
for (Cleaner.CleanerRule cleanerRule : cleaner.getCleanerRules()) {
if (cleanerRule.getCleanType() == Cleaner.CleanType.MERGE) {
List<JSONObject> queryResult = mongoTemplate.find(new BasicQuery(cleanerRule.getQueryRule()),
JSONObject.class, ultimateSpider.getSpiderName());
Map<String, List<JSONObject>> mergeMap = Maps.newHashMap();
queryResult.forEach(result -> {
List<String> keyItems = Lists.newLinkedList();
for (String distinctKey : cleanerRule.getDistinctKeys()) {
StringBuilder keyItemBuilder = new StringBuilder();
if (!result.containsKey(distinctKey)) {
break;
}
keyItemBuilder.append(distinctKey).append(Constants.MERGE_KEY_DELIMITER).append(result.get(distinctKey));
keyItems.add(keyItemBuilder.toString());
}
if (keyItems.size() == cleanerRule.getDistinctKeys().size()) {
String mergeKey = StringUtils.join(Constants.MERGE_VALUE_DELIMITER, keyItems);
List<JSONObject> resultMergeList = mergeMap.getOrDefault(mergeKey, Lists.newArrayList());
resultMergeList.add(result);
mergeMap.putIfAbsent(mergeKey, Lists.newArrayList());
}
});
mergeMap.forEach((mergeKey, resultMergeList) -> {
if (resultMergeList.size() > 1) {
purgeList.addAll(resultMergeList);
JSONObject mergeResult = resultMergeList.get(0);
resultMergeList.remove(0);
resultMergeList.forEach(result -> {
for (String resultMergeKey : cleanerRule.getMergeKeys()) {
if (mergeResult.get(resultMergeKey) instanceof JSONArray) {
JSONArray jsonArray = (JSONArray) mergeResult.getOrDefault(resultMergeKey, new JSONArray());
if (!jsonArray.contains(result.get(resultMergeKey))) {
jsonArray.add(result.get(resultMergeKey));
mergeResult.put(resultMergeKey, jsonArray);
}
} else {
JSONArray jsonArray = new JSONArray();
jsonArray.add(mergeResult.get(resultMergeKey));
jsonArray.add(result.get(resultMergeKey));
mergeResult.put(resultMergeKey, jsonArray);
}
}
});
mergeList.add(mergeResult);
}
});
} else if (cleanerRule.getCleanType() == Cleaner.CleanType.PURGE) {
purgeList.addAll(mongoTemplate.find(new BasicQuery(cleanerRule.getQueryRule()),
JSONObject.class, ultimateSpider.getSpiderName()));
}
}
purgeList.forEach(purgeObject -> mongoTemplate.remove(purgeObject, ultimateSpider.getSpiderName()));
mergeList.forEach(mergeObject -> mongoTemplate.save(mergeObject, ultimateSpider.getSpiderName()));
}
}
|
数据持久化
使用RabbitMQ消息队列异步保存爬取结果至MongoDB文档型数据库,性能更好,更适合格式多变的爬取结果的存储。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| @Slf4j
@Component
@RabbitListener(queues = Constants.QUEUE_NAME)
public class Receiver {
@Autowired
private MongoTemplate mongoTemplate;
@RabbitHandler
public void receive(String spiderResultJson) {
SpiderResult spiderResult = JSON.parseObject(spiderResultJson, SpiderResult.class);
log.info("queue: {}, spider_result: {}", Constants.QUEUE_NAME, spiderResult);
mongoTemplate.save(spiderResult.getContent(), spiderResult.getSpiderName());
}
}
|
数据可视化
使用较为成熟的Metabase进行采集数据的可视化。