
可容灾分布式系统设计
可容灾分布式系统设计
基本概念
后台开发的目标是要提供高可用的后台服务,其中很重要的一点是保证业务连续性(服务不中断,或中断时间在允许范围内)。要保证业务连续性,系统需要具备容灾能力。
所谓容灾,就是对灾难(disaster)的容忍能力,即在灾难袭来时,能够保证信息系统正常运行而采取的措施,以实现业务连续性为目标。
衡量指标
衡量容灾系统的主要指标有RPO(Recovery Point Objective,灾难发生时允许丢失的数据量)、RTO(Recovery Time Objective,系统恢复的时间)、容灾半径(生产系统和容灾系统之间的距离)以及ROI(Return of Investment,容灾系统的投入产出比)。
RPO:业务系统所允许的灾难过程中的最大数据丢失量(以时间来度量),这是一个灾备系统所选用的数据复制技术有密切关系的指标,用以衡量灾备方案的数据冗余备份能力。
RTO:将信息系统从灾难造成的故障或瘫痪状态恢复到可正常运行状态,并将其支持的业务功能从灾难造成的不正常状态恢复到可接收状态所需的时间,其中包括备份数据恢复到可用状态所需时间、应用系统切换时间、以及备用网络切换时间等,该指标用以衡量容灾方案的业务恢复能力。例如,灾难发生后半天内便需要恢复,则RTO值就是十二小时。
容灾半径:生产中心和灾备中心之间的直线距离,用以衡量容灾方案所能防御的灾难影响范围。
ROI:用户投入到容灾系统的资金与从中所获得的收益的比例。
显然,具有零RTO、零RPO和大容灾半径的灾难恢复方案是用户最期望的,但受系统性能要求、适用技术及成本等方面的约束,这种方案实际上是不大可行的。所以,用户在选择容灾方案时应该综合考虑灾难的发生概率、灾难对数据的破坏力、数据所支撑业务的重要性、适用的技术措施及自身所能承受的成本等多种因素,理性地作出选择。
容灾级别
根据冗余对象,容灾大致可以分为数据级容灾、应用级容灾和业务级容灾。
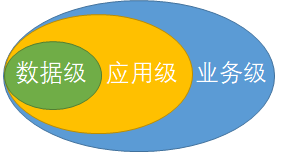
数据级容灾
数据备份,如建立异地容灾中心做数据远程备份(只备份数据,没有备份系统可切换)。
容灾中心的数据可以是本地生成数据的完全复制(一般在同城实现),也可以比生产数据略微落后,但必定是可用的(一般在异地实现),而差异的数据通常可以通过一些工具(如操作记录、日志等)进行手动补回。基于数据容灾实现业务恢复的速度较慢,通常情况下RTO超过24小时,但是这种级别的容灾系统运行维护成本较低。
应用级容灾
在数据容灾的基础上构建一套功能相同的系统,可做系统切换。
容灾中心需要建立起一套和本地生成相当的备份环境,包括主机、网络、应用、IP等资源均有配套,当生产系统发生灾难时,异地系统可以提供完全可用的生产环境。应用级容灾的RTO通常在12个小时以内,技术复杂度较高,运行维护的成本也比较高。
业务级容灾
在应用容灾基础上,增加了IT系统以外的容灾。如备用办公地点,系统相关文档等。
业务级容灾是生产中心与容灾中心对业务请求同时进行处理的容灾方式,能够确保业务持续可用。这种方式业务恢复过程自动化程度高,RTO可以做到30分钟以内。但是这种容灾级别的项目实施难度大,需要从应用层对系统进行改造,比较适合流程固定的简单业务系统。这种容灾系统的运行维护成本最高。
评价指标
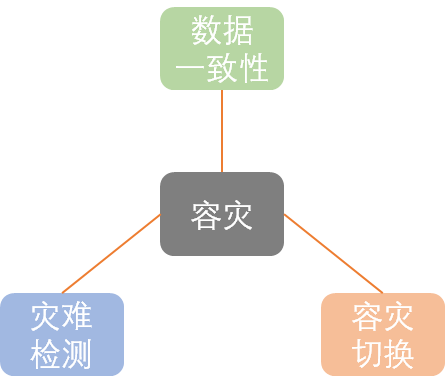
容灾系统有三个重要的评价指标。
灾难检测:具备容灾能力的系统需要能够检测出哪个子系统、组件发生了灾难,以便决策解决方案(灾难恢复)。
容灾切换:系统检测到某个子系统、组件故障后,要具备把流量切换到其他具备相同能力的子系统上去的能力。
数据一致性:同功能的不同子系统(主备)之间的数据要保持一致。灾难恢复后的业务应该不受影响。理论上用户对灾难是无感知的。
解决方案
双活
双活是指在两个生产中心部署相同的两个能力相同的业务系统。两个系统同时工作,地位对等、不分主从。具备在对方系统灾难发生时,接管对方业务的能力。
双活通常需要负载均衡技术的支持。
多活与双活区别在生产中心的数量上。
双活有同城双活和异地双活,主要是地理位置上的区别。
灾备
这里灾备是指具有主从之分的灾备系统(双活是不分主从的灾备)。
通常是建立一个主业务系统和一个从属(备用)的业务系统(可能只有数据中心),正常情况下仅有主业务系统在工作。在主业务系统故障时,再启用备用系统。
灾备有热备、冷备等方式。
热备:备用数据中心对主数据中心的数据实时备份。在容灾切换时,业务不会中断。
冷备:备用数据中心只是对主数据中心的数据进行定期备份(或者异步备份)。在容灾切换时,业务可能会中断。
热备和冷备的成本要考虑是仅做数据中心备份,还是有业务系统的备份。如果仅仅是数据的备份,那么其成本主要是存储设备的成本(硬盘);如果做了业务系统的备份,则成本与双活差不多,而且由于备用系统长期不工作,会造成资源浪费。
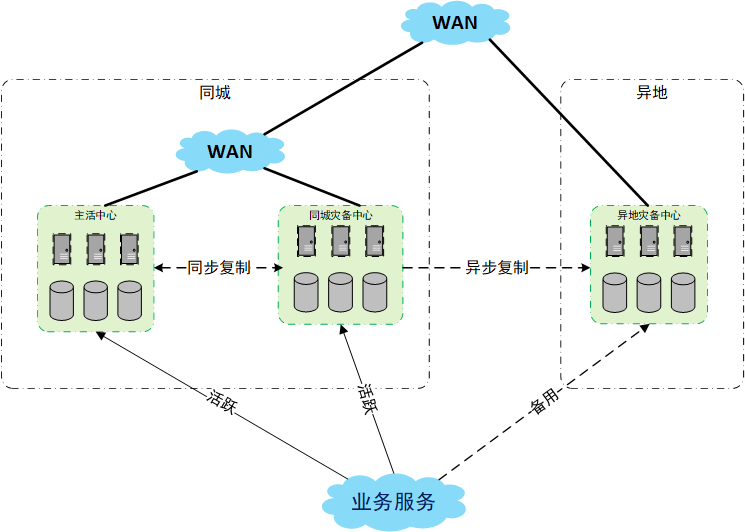
两地三中心
两地三中心是指在同城和异地同时建立灾备中心。
同城灾备中心通常采用热备的方式,并一般会提供业务服务。异步灾备中心只是做数据的备份,且数据的复制是异步的。异步灾备中心平时不提供业务服务。
容灾系统设计
容灾系统的设计不是一成不变的,不同的应用场景通常会有一些定制化的设计。因为容灾通常是基于服务冗余实现的,大而全的容灾系统具有较大的成本。
常见的四层容灾设计如下:
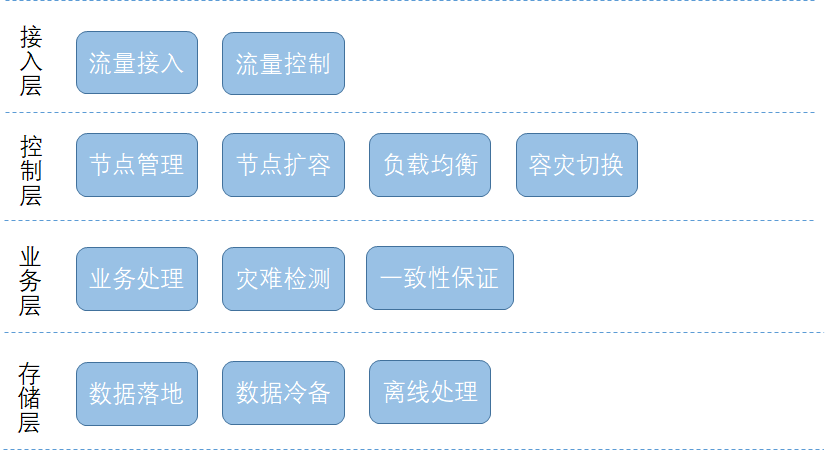
接入层:负责流量的接入和路由。
控制层:负载均衡、节点管理等。
业务层:处理请求,负责具体的业务逻辑,可能涉及数据的读写。
落地层:数据的落地存储。
灾难检测可以在控制层或业务层。
注:本文所介绍的容灾主要是业务层以下的容灾。
实现细节
容灾的内部实现是多种多样的,不同的公司可能都有自己的实现技术。下面知识介绍一些案例或常用的实现。主要是为了阐述可能的实现原理,不一定适用所遇场景。
灾难检测
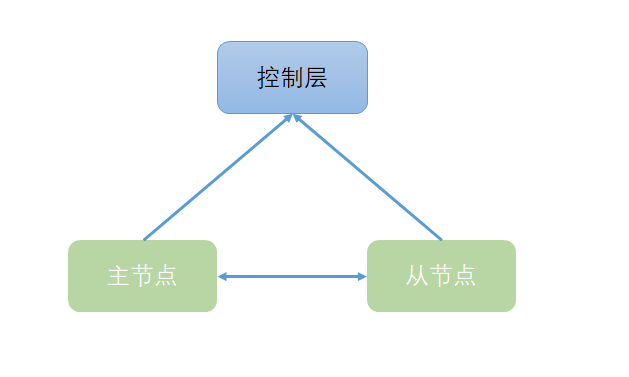
容灾系统通常是一个集群,集群中有多个节点,通常是一个主节点(master)和一个以上的从节点(slave)。
灾难检测可以通过心跳包实现。
主节点和从节点分别向控制层上报心跳,如果控制层收不到某个节点的心跳,则认为其不可用,对主节点降级,并把流量切到从节点。
更为严谨的做法是,节点之间也互相上报心跳,这样可以做孤岛检测。
容灾切换
容灾切换主要是把流量从一个节点切到其他节点。可以通过负载均衡等系统实现。
数据一致性
数据一致性是要保证各个节点的数据一致,这样在主节点故障,切换到其他节点时才能保证业务不中断,不受影响。
在业务处理过程中,可能涉及到频繁的数据读写,有些业务请求需要等待写成功后才能返回给用户。要保证各个节点的数据在存储落地时一致,需要等到所有节点都写成功后再返回,这就涉及到同步写。
按上面的逻辑,为保证数据一致性,客户端、主节点和备用节点会发生以下交互。
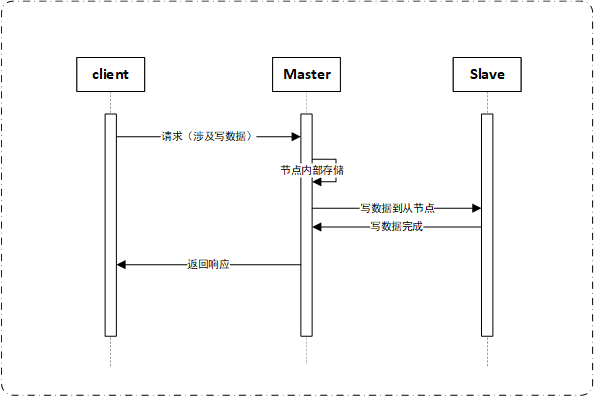
由于master和slave再地理位置上可能相隔较远,因而这种同步写的方式有可能造成一定的延迟,影响系统性能,增加了请求的响应时间。
为了减少延迟(减少容灾对系统性能产生的影响)可以对数据一致性的实现做一些改进。
下面介绍两种改进方式。
- 数据分级,允许不重要数据少量丢失。
- 优化设计,变同步为异步。
数据分级的方式,主要是减少需要同步写的对象,对不重要的数据,允许再一定程度内丢失。
然而再很多场景下,数据分级的方式并不适用。
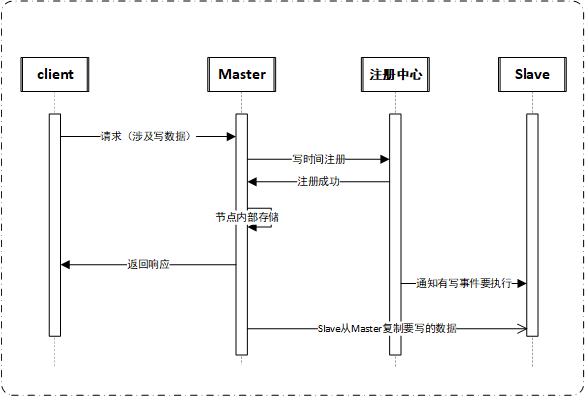
第二种方式是现在常用的保证数据一致性,又降低对系统性能影响的方式。在这种设计下,增加了一个组件(注册中心)用于登记写事件。
master再存储数据时,先到注册中心登记下,然后再进行写动作,同时通知slave需要复制数据。master再写动作完成后即可返回给client,不需要等到slave写动作完成。也就是slave是以异步的方式从master那里复制数据。
那么这种设计如何保证数据一致性呢?
- master在注册中心登记了写事件,slave可以与注册中心校验与master是否数据一致。
- 验证结果为数据一致,不需要额外处理。
- 验证结果为数据不一致,则尝试从master复制未写的数据。
- 尝试复制成功,则数据同步完成。
- 尝试复制事变,则通知注册中心回滚(做下标志),同时通知客户端上次写事件失败,需要重新发起请求。
时序图:
注册中心的等级同样是同步操作,为何能降低性能影响?
- 注册写事件涉及到的数据内容通常远小于业务数据。
- 在多节点时,写事件的注册比各节点的数据同步要快很多。




